I’m trying to write a new programming language and will document some ideas and problems that I’m encountering here.
The elementary structure of my compiler is as follows:
- lexing
- parsing
- AST postprocessing
- semantic analysis
- code generation
I’ll explain these terms using a simple evaluator for mathematical expressions. Valid expressions start with a number and then follow any number of “operand number pairs”. So 9, 4 * 5 are valid, but a, 9 x or 4 * x are not. Variables are not supported in this example.
The lexer converts a stream of characters from the input file into a stream of tokens. In my example that means that the string 9 – 3 * 3 is converted to the tokens
NUMBER(9) MINUS(-) NUMBER(3) MULTIPLY(*) NUMBER(3)
An important task of the lexer is to reject inputs which don’t match the rules of any token, like a * 3 X.
The next step is parsing this stream of tokens and building a parse tree or more specifically an AbstractSyntaxTree. An AST is a data structure that allows the computer to evaluate an expression in a very convenient way while respecting operator precedence. The result looks like this:
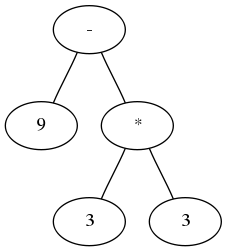
AST for the expression 9 - 3 * 3
In general every AST node has a type, text field and any number of children. Additional information like line and character position information are useful, but not necessary.
Again the parser is responsible for rejecting inputs which do not conform to the grammar of the language. While 21 + * 21 is lexed correctly it does not match the rules for mathematical expressions and so it is rejected by the parser.
The phase of AST postprocessing is not relevant for this simple example. I’ll write about this phase in another post about my compiler.
Semantic analysis: Without evaluating the AST we can only do really simple things like making sure that a DIVIDE node never has a zero as a right operand. Again in another post I’ll write more details about this phase.
Code generation: Instead of discussing code generation I’ll first take a look back at the AST to see how a computer can calculate the result of the original expression.
Starting at the top we have a - node with two children, one being a number and the other a * node. So we can’t calculate the value of the - node until we know the result of the * node. Using recursion we jump to the * node and look at it’s children.
Both are numbers, so we can calculate the value of the * node: 9. Going back to the - node we now have two numbers as children and we can calculate the final result: 0.
So the great advantage of an AST is, that it’s a fairly simple way of encoding data together with operator precedence.
Instead of interpreting the AST my compiler generates code, but the basic idea stays the same: Starting at the root node I call functions which are equivalent to the operation that the current AST node stands for and use recursion to emit the code for nested expressions.
The next post in this series will be about the tools I’m using to create my compiler.